Covid On The Web
Date:
Date:
Mis à jour le 26/11/2020
Porteur : Fabien Gandon, responsable de l'équipe-projet Wimmics
Partenaires : Université Côte d'Azur, CNRS, I3S
Aide à l'utilisation de la littérature scientifique sur les coronavirus
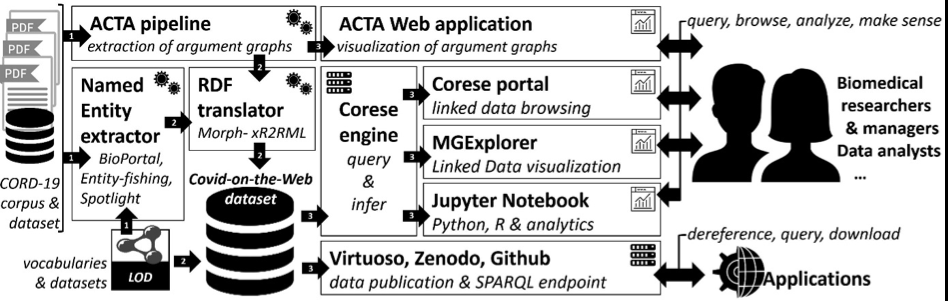
L'objectif est de permettre aux chercheurs du domaine biomédical d'accéder plus facilement à la littérature relative au Covid-19, de l'interroger et de lui donner un sens. Nous avons conçu une chaîne de traitement pour enrichir en permanence un graphe de connaissances à propos du Covid et des outils logiciels pour l'exploiter, en tirant parti de notre expertise en représentation des connaissances, de la fouille de textes, de données et d’arguments, et de la visualisation et de l'exploration des données. Le chaîne de traitement extrait les entités nommées dans les articles (DBpedia, Wikidata et autres vocabulaires du Bioportal) ainsi que des graphes argumentatifs, destinés à aider les cliniciens à analyser les essais cliniques et à prendre des décisions. En plus de ce graphe de connaissances, nous avons développé, adapté et déployé plusieurs outils fournissant des visualisations et des méthodes d'exploration et des notebooks pour les scientifiques voulant utiliser ces données.
Des scientifiques de tous les domaines mettent à profit leur expertise et leurs ressources multidisciplinaires pour lutter contre la pandémie de Covid-19. Pour contribuer à cet effort, l'équipe Wimmics a décidé de profiter de la période de confinement pour lancer le projet Covid-on-the-Web comme un sprint afin d'adapter et de combiner ses méthodes, modèles et outils (ACTA, Corese, MGExplorer, Morph-xR2RML) pour traiter, analyser et enrichir le corpus "Covid-19 Open Research Dataset" (CORD-19) qui rassemble plus de 50 000 articles scientifiques en texte intégral relatifs aux coronavirus.
Extraire, publier et visualiser un graphe de connaissances sur le Covid
L'objectif est de permettre aux chercheurs du domaine biomédical d'accéder plus facilement à la littérature relative au Covid-19, de l'interroger et de lui donner un sens. Nous avons conçu une chaîne de traitement pour enrichir en permanence un graphe de connaissances à propos du Covid et des outils logiciels pour l'exploiter, en tirant parti de notre expertise en représentation des connaissances, de la fouille de textes, de données et d’arguments, et de la visualisation et de l'exploration des données. Le chaîne de traitement extrait les entités nommées dans les articles (DBpedia, Wikidata et autres vocabulaires du Bioportal) ainsi que des graphes argumentatifs, destinés à aider les cliniciens à analyser les essais cliniques et à prendre des décisions. En plus de ce graphe de connaissances, nous avons développé, adapté et déployé plusieurs outils fournissant des visualisations et des méthodes d'exploration et des notebooks pour les scientifiques voulant utiliser ces données.
Répondre aux scénarios motivants et aux questions de compétences des institutions biomédicales
Plusieurs institutions biomédicales ont manifesté leur intérêt pour l'utilisation de nos ressources, qu'elles soient partenaires directs du projet (Institut français de recherche médicale - Inserm, Institut national du cancer - INCa) ou indirects (par exemple, l'hôpital d'Antibes, l'hôpital de Nice). Pour l'instant, ces institutions agissent en tant qu'utilisatrices potentielles des ressources et en tant que coconceptrices. Grâce à des discussions actives avec l'INCa et l'INSERM, nous nous assurons que notre approche est guidée par et alignée sur les besoins réels de la communauté biomédicale. Avec une approche orientée vers l'utilisateur, nous concevons les outils et les ressources selon des scénarios motivants identifiés par une analyse des besoins des institutions biomédicales. L'un des tout premiers exemples d'interrogation sur lequel ils nous ont suggéré de travailler a été de "trouver tous les articles qui parlent à la fois d'un type de cancer et d'un virus de type corona". Nous obtenons constamment de nouvelles requêtes intéressantes de la part des utilisateurs potentiels que nous interrogeons, et ces requêtes servent à préciser et à tester notre graphe de connaissances et nos services.

L’épidémie de SARS-Cov-2 est liée à un virus dit émergent. Depuis son apparition en décembre 2019 en Chine et son émergence à l’échelle mondiale à partir de janvier 2020, les effets de ce virus sont découverts progressivement en parallèle de la progression de l’épidémie, comme par exemple le large spectre des organes affectés (ORL, poumon, système nerveux, peau, etc.).
Cependant, les liens entre SARS-Cov-2 (formes asymptomatique, sévères voire d’éventuelles réinfections) et cancer ne sont pas connus. Par ailleurs, le rôle de plusieurs virus dans le développement de différents types de cancer est démontré (ex : HPV, HBV, EBV, etc.) ou soupçonné plus ou moins fortement (monographies CIRC).
Ainsi, outre le devenir des patients souffrant d’un cancer et atteints secondairement de SARS-Cov-2, le rôle du virus à moyen ou long terme dans la prédisposition à l’apparition d’un cancer, son éventuelle implication dans l’évolution ou dans l’apparition d’un second cancer ne peuvent être exclues (ex : pulmonaire, ORL, cerveau etc.). Par ailleurs, et de façon rétrospective, il serait pertinent d’étudier l’impact des deux premières épidémies dues à des coronavirus : SARS-CoV1 et MERS-CoV, apparues respectivement en 2002 en Asie du Sud-Est et en 2012 au Moyen-Orient sur le développement a posteriori de cancer et plus largement leur impact en lien avec le cancer.
C’est dans ce contexte que la collaboration entre l’INCa et l’équipe Wimmics est née.
Verbatim
En effet, l’expertise de l’équipe Wimmics dans le Web sémantique est apparue comme nécessaire et incontournable pour identifier les liens potentiels entre cancer et coronavirus. L’équipe peut en effet traduire en requêtes spécifiques des échanges informels ou des hypothèses de recherche afin de remonter l’ensemble des données pertinentes. Cette collaboration met d’autant plus en exergue la complémentarité et la nécessité de développer des outils de recherche avancés permettant la remontée d’informations de tout type (non limitées aux journaux à comité de lecture) afin d’étudier les liens potentiels entre cancer et infection par un des coronavirus. Ce travail permettra d’autant plus d’anticiper l’impact éventuel sur le développement d’un cancer ainsi que de proposer une programmation adaptée en fonction des questions de recherche qui seront identifiées.
Auteur
Poste
Responsable des affaires scientifiques, Division Recherche et Innovation de l'INCa