Analyse et traitement d'images
Vers une meilleure reproductibilité des résultats en neuro-imagerie
Date:
Date:
Mis à jour le 12/10/2023
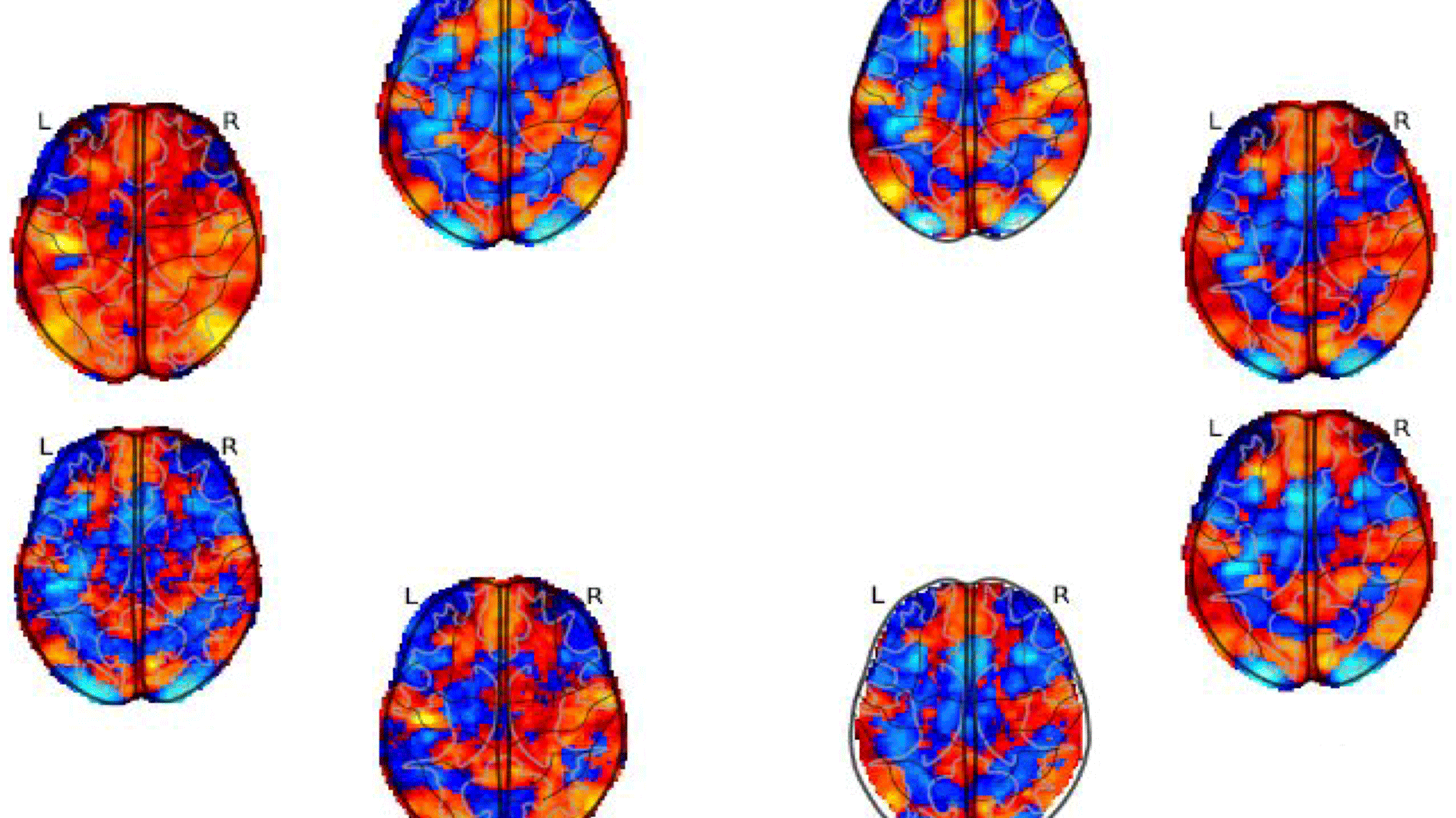
Huit cartes statistiques de la même expérience d'imagerie par résonance magnétique fonctionnelle (IRMf) testant l'effet paramétrique négatif de la perte dans la tâche de paris du projet NARPS.
« Mille papiers scientifiques pour rien ». Paru sous un titre un peu provocateur en 2019, dans The Atlantic, un article racontait comment, à la fin du siècle dernier, une étude avait établi l’influence du gène SLCA4 sur la dépression. Et surtout comment cette découverte majeure avait influencé les chercheurs du domaine. Pendant 20 longues années, les résultats avaient servi d’appui à un bon millier de publications. Et puis patatras. Les conclusions initiales se sont révélées fausses. Tout le corpus ultérieur de recherche s’est alors effondré comme un château de cartes. Moralité ? La reproductibilité des résultats scientifiques est une question de recherche en soi. Et la neuro-imagerie n'est pas externe à ce problème.
En 2020, dans la revue Nature, avec plusieurs collègues, le scientifique Rotem Botvinik-Nezer se livrait à une expérience : confier un même jeu de données à 70 pipelines de neuro-imagerie. Puis passer au crible les résultats en sortie. En l’occurrence, il s’agissait d’établir un lien, ou pas, entre une tâche à effectuer et l’activation d’une zone du cerveau. Mauvaise surprise : tous les pipelines n’ont pas livré les mêmes conclusions.
C’est ce constat qui vient d’amener Camille Maumet à entreprendre une action exploratoire visant à réduire la variabilité dans les chaînes de traitement. Membre de l’équipe de neuro-imagerie Empenn, la chercheuse s’intéresse à la reproductibilité des résultats au sens large.
Une première question porte sur les données elles-mêmes. En particulier la taille des échantillons. « Si l’analyse repose sur un groupe de participants assez petit, alors on sait qu’il existe plus de risques d’avoir de faux positifs. Un autre problème peut venir du manque de représentativité de l’échantillon par rapport à la population générale. Avec combien de participants à une étude peut-on vraiment représenter cette diversité humaine ?» Complication supplémentaire : pour les maladies rares, les bases constituées localement comprennent à chaque fois peu de cas. Tout cela milite pour le partage des données afin de constituer « des échantillons plus grands, plus divers, plus représentatifs de la population. » Dans une thèse coencadrée par Camille Maumet et Elisa Fromont, de l’équipe Lacodam (Inria / Université de Rennes / INSA Rennes / Institut Agro Rennes-Angers - Irisa), Elodie Germani a pu mettre en œuvre cette approche et démontrer que les modèles créés avec de grandes bases diverses sont plus adaptables sur de nouvelles données.
Le partage est d’ailleurs l’une des pierres angulaires du mouvement pour une science ouverte que prônent de nombreux chercheurs. Mais pour que les données soient partagées, encore faut-il qu’elles soient partageables. Pas si simple. « Une équipe de recherche peut mettre ses données en ligne et dire : servez-vous ! Pourtant, en pratique, cela ne suffit pas. » Car beaucoup de questions surgissent. « Le format de ces données est-il compréhensible par d’autres utilisateurs ? A-t-on suffisamment de descriptions pour savoir si l’échantillon comporte dix, vingt ou trente participants ? Comment sait-on que plusieurs images appartiennent à une seule personne ? Dans l’hypothèse où un protocole particulier a été élaboré, celui-ci est-il décrit ? Et ainsi de suite. »
Conclusion ?
Image

Verbatim
Les données seules sont souvent inexploitables. Il faut rajouter de l’annotation. Mais cela prend du temps. Surtout quand le scientifique a déjà beaucoup de travail. De plus, il faut annoter avec l’idée de rendre les données réutilisables. Or l’espace d’annotation est très vaste. Il faut donc opérer des choix. Se poser la question de quelles annotations spécifiquement pourront servir à d’autres. J’ai des travaux pour proposer des recommandations dans ce sens.
Auteur
Poste
Chargée de recherche - équipe EMPENN
Des considérations légales entrent aussi en ligne de compte. En particulier en Europe où le Règlement général sur la protection des données (RGPD) encadre strictement l’accès aux informations personnelles. À cet égard, Empenn s’est associée à d’autres équipes de recherche dans un projet appelé OpenBrainConsent. « Nous avons élaboré des modèles de documents multilingues (en français en collaboration avec Elise Bannier et Anne Hespel du CHU de Rennes) que les utilisateurs doivent signer avant de commencer une étude. Dans ce code de conduite, les scientifiques s’engagent à ne pas désanonymiser les données, à ne pas utiliser les données d’une personne qui en ferait la demande, etc. Il y a encore des travaux à faire dans cette direction avec des juristes pour résoudre des questions pratiques afin de respecter la vie privée tout en permettant à la science d’avancer. »
Dans le cadre d’OpenBrainConsent et avec le chercheur Cyril Pernet, de l’Université d’Edinburgh, Camille Maumet porte une action européenne Cost appelée GLIMR. L’objectif : mettre en commun des données sur l’étude des gliomes. Pour ces tumeurs cérébrales rares, les échantillons dans chaque laboratoire sont donc très petits. Ce qui nécessite a fortiori un partage.
La seconde grande question concerne la robustesse des outils. Et plus exactement « comment différentes façons de traiter nos données vont impacter les résultats que l’on obtient. » En réalité, beaucoup de facteurs s’invitent dans l’équation. « Tout au long d’un pipeline, on trouve de multiples étapes de traitement. Pour chacune, il faut opérer plein de choix. Par exemple, pour sélectionner l’outil le mieux adapté. Ensuite, dans cet outil lui-même, il peut y avoir plusieurs algorithmes. Et chacun de ces algorithmes, à son tour, propose toute une série de paramètres parmi lesquels, à nouveau, il faut choisir. Or ces choix successifs impactent les résultats. Évidemment, l’expérience des neuro-scientifiques permet de réduire quelque peu l’espace de choix, mais celui-ci reste quand même énorme.”
Avec le soutien de Boris Clénet (ingénieur) et Jérémy Lefort-Besnard (postdoctorant), l’action exploratoire Grasp va s’intéresser plus spécifiquement à ce deuxième aspect. Pour ce faire, elle s’appuiera sur l’étude de Botvinik-Nezer. « C’est un cas d’usage hyper intéressant car on dispose de vrais pipelines conçus par des chercheurs et d’une description détaillée des traitements. Dans un premier temps, nous souhaitons récupérer également le code de ces 70 pipelines. En comparant ce code avec la description des traitements effectués et le résultat obtenu, nous voulons d’abord comprendre pourquoi, en changeant de pipeline, on obtient une réponse différente. Peut-être que l’outil fonctionne mal et que personne ne s’en est rendu compte. Peut-être que le pipeline choisi n’est pas adapté pour répondre au problème. Ou alors le paramétrage n’est pas le bon. »
Ce paramétrage peut aussi faire apparaître ou disparaître des phénomènes d’intérêt dans le jeu de données.
Si je choisis d’ajouter la variable liée à l’âge et que j’obtiens un résultat différent, alors l’âge est un facteur ayant un effet sur le phénomène que j’observe. Dans ce cas, c’est la variabilité qui m’informe sur mon problème.
En comparant ainsi les mécaniques à l’œuvre dans les pipelines, l’action exploratoire ambitionne de pouvoir ensuite guider les scientifiques dans la succession de choix qu’ils effectuent.
C’est notre deuxième axe. Nous voulons proposer une méthode statistique pour éclairer les chercheurs de neurosciences en leur disant : attention, il y a de la variabilité analytique ! Au lieu de lancer une seule chaîne de traitement, lancez-en plusieurs. À partir de là, l’idée de notre méthode serait de produire une sorte de résumé : si j’ai 10 chaînes de traitement, puis-je combiner les résultats pour en obtenir un seul ?
En exploitant cette immense combinatoire d’outils, de codes et de paramétrages, on pourrait même imaginer de produire un modèle logique. Autrement dit : l’arbre complet de l’ensemble des possibles. « Cela ne fait pas partie de l’action exploratoire. Mais éventuellement l’étape d’après…»
Visuel

Titre du lecteur
En savoir plus sur le projet GRASP
Fichier audio
Audio file